






战斗机非定常外流场CFD仿真:从纳维-斯托克斯方程到AI增强可视化的算力革命
时间:2026-03-04 00:38:55
来源:UltraLAB图形工作站方案网站
人气:73
作者:管理员
当即梦Seedance 2.0成功"读懂"CFD云图并在全新机动轨迹上实时生成物理一致的尾流演化时,我们见证了计算流体力学(CFD)技术范式的重大转变——数值仿真不再只是静态的结果输出,而是可以与AI生成技术融合的动态知识库。对于航空工程、飞行器设计和军事科研领域,这意味着从"眼镜蛇机动"到"滚筒机动"的复杂非定常流场分析,正在经历从超算中心到桌面工作站的算力民主化。
本文针对战斗机非定常外流场仿真、高雷诺数湍流模拟、大涡模拟(LES)与分离涡模拟(DES)、以及AI增强流场可视化四大核心场景,深度解析其计算特征、软件栈与硬件配置方案。
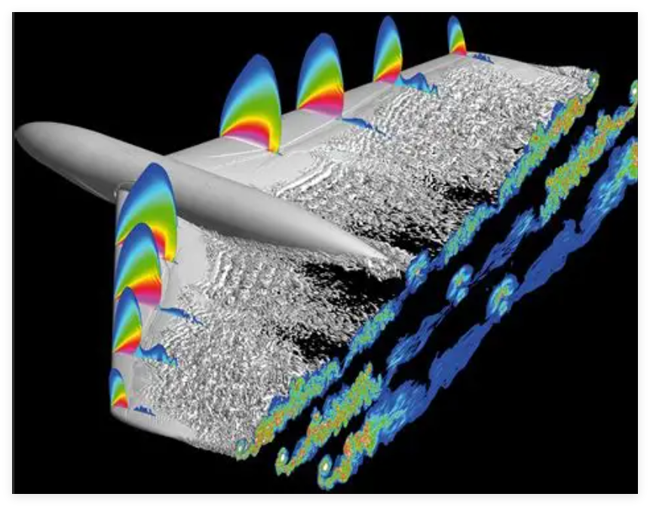
一、应用场景计算特点深度剖析
1. 非定常外流场全机仿真:高雷诺数与大分离流动的双重挑战
计算特征(对应文中"眼镜蛇机动"、"急盘旋"等场景):
-
网格规模爆炸:战斗机全机仿真需解析边界层、尾涡、激波等细微结构,非定常LES/DES网格量通常在1-5亿单元(全机精细模拟可达10亿+)
-
时间步长严苛:非定常模拟需解析涡脱落频率(通常10-1000Hz),时间步长需控制在微秒级(1e-5~1e-6秒),总物理时间常需模拟数秒至数分钟,对应数十万时间步
-
湍流模型计算密集:LES的亚格子尺度(SGS)模型或DES的混合RANS/LES切换,每个时间步需在网格单元上求解额外的输运方程,计算量是定常RANS的50-100倍
硬件瓶颈:内存容量成为首要瓶颈(10亿网格单精度需~40GB内存,双精度~80GB),存储I/O压力巨大(每时间步输出瞬态结果,秒级物理时间可产生TB级数据)。
2. 尾流涡系演化模拟:大涡模拟(LES)的频谱解析需求
计算特征(对应文中"翼尖涡"、"尾流耗散"分析):
-
高阶格式需求:为准确捕捉涡核结构(vortex core),空间离散需采用4阶以上WENO或DG格式,计算密度显著高于2阶格式
-
并行效率挑战:尾流涡系具有长距离相关性,并行分区时需最小化界面通信,对网络带宽与延迟极度敏感
-
后处理可视化负载:涡识别(Q-criterion, λ2-criterion)、等值面提取、粒子追踪等后处理操作,需在GPU加速下实现实时交互
3. 多体分离与机动轨迹耦合:流固耦合(FSI)与动网格
计算特征(对应文中"飞机沿着虚线机动"):
-
动网格(Dynamic Mesh)开销:每时间步需更新网格位置(弹簧光顺、局部重生成),网格变形计算占总时间30-50%
-
六自由度(6-DOF)求解:实时计算气动力→更新姿态→反馈流场,强耦合迭代需双路通信机制
-
非定常气动力数据库:构建文中提到的"机动参数-尾流特征"映射关系,需进行成百上千次参数化仿真,产生蒙特卡洛级计算需求
4. AI增强流场可视化与实时推演:深度学习推理负载
计算特征(对应即梦Seedance 2.0的技术路线):
-
CNN/Transformer推理:将CFD结果作为条件输入,生成时间序列流场动画,需批量处理高分辨率体数据(3D张量)
-
物理信息神经网络(PINN):用神经网络求解NS方程的逆问题(从视频反推气动力参数),训练过程需大显存GPU(48GB+)
-
实时渲染:路径追踪(Path Tracing)渲染涡结构,需RTX级显卡的光追核心
二、核心软件工具链与系统架构
(一)任务关键软件清单
表格
| 功能层级 | 软件类型 | 代表软件/开源方案 | 授权类型 | 典型用途 |
|---|---|---|---|---|
| 前处理 | 几何清理与网格生成 | ANSYS SpaceClaim, Pointwise, ANSA, Gmsh, Salome | 商业/开源 | 战机外形修复、边界层网格( inflation layer)生成 |
| 网格划分 | ICEM CFD, TetGen, cfMesh (OpenFOAM) | 商业/开源 | 混合网格(棱柱+四面体+六面体) | |
| 求解器 | 通用CFD商业软件 | ANSYS Fluent, Siemens STAR-CCM+, Altair ultraFluidX | 商业 | 全机定常/非定常RANS,DES |
| 开源CFD平台 | OpenFOAM (v2312), SU2, FEniCS | 开源 | 自定义湍流模型,LES研究 | |
| 高阶精度求解器 | Nektar++, PyFR, HiFiLES | 开源/学术 | 谱元法(SEM)高阶模拟尾涡 | |
| 可压缩流动专用 | US3D, FUN3D (NASA), CFD++ | 学术/商业 | 高超声速、激波-边界层干扰 | |
| 湍流与转捩 | LES/DES模型 | OpenFOAM LES模块, CharLES (Cascade) | 开源/商业 | 大涡模拟,延迟DES(DDES) |
| 转捩预测 | γ-Reθ模型 (Fluent), LSTe (线性稳定性) | 商业/学术 | 层流-湍流转捩预测 | |
| 后处理 | 可视化 | ParaView, Tecplot 360 EX, FieldView, VisIt | 开源/商业 | 涡识别、等值面、流线 |
| 数据分析 | Python (Matplotlib, PyVista), MATLAB | 开源/商业 | 频谱分析、本征正交分解(POD) | |
| AI融合 | 深度学习框架 | PyTorch, TensorFlow, NVIDIA Modulus (SimNet) | 开源 | PINN流场重构、涡识别AI |
| AI可视化 | NVIDIA Omniverse, ParaView Neural Network | 商业/开源 | 实时流场渲染、AI超分辨率 |
(二)系统安装清单(CFD高性能计算节点)
操作系统层:
-
服务器/集群:CentOS Stream 9 / Rocky Linux 9 / Ubuntu Server 22.04 LTS
-
内核参数优化:
vm.swappiness=10,vm.dirty_ratio=40(减少I/O阻塞) -
文件系统:BeeGFS/Lustre(并行文件系统)或 XFS(本地高速存储)
-
-
工作站:Windows 11 Pro for Workstations(兼容商业CFD GUI)+ WSL2(Ubuntu 22.04,用于OpenFOAM开发)
编译与运行时环境:
-
编译器:GCC 12.2+, Intel oneAPI (icx/icpx/ifort), NVIDIA HPC SDK (nvcc/nvc++)
-
并行库:OpenMPI 4.1+ 或 Intel MPI,Intel oneMKL(BLAS/LAPACK)
-
GPU加速:CUDA Toolkit 12.3+, cuDNN 8.9+, NVIDIA OptiX(光线追踪)
-
容器化:Docker + NVIDIA Container Toolkit(确保GPU在容器中可用)
CFD专用依赖:
-
OpenFOAM第三方库:PT Scotch(网格分解)、METIS、ParMGridGen
-
网格工具:CGNS库、HDF5(支持大文件>2GB)
三、硬件配置推荐方案
方案A:非定常全机LES仿真工作站——超大规模内存型
定位:支持5-10亿网格单元战斗机的完整非定常LES/DES计算,单节点完成中小规模任务,减少跨节点通信开销。
| 组件 | 配置规格 | 技术 rationale |
|---|---|---|
| CPU | 双路 AMD EPYC 9654(96核×2,共192核,基频2.4GHz,Boost 3.7GHz) | 高核心数支持OpenFOAM大规模并行,高内存带宽(DDR5-4800,每路12通道) |
| 内存 | 3TB DDR5-4800 RDIMM ECC(24×128GB) | 10亿网格双精度需~80GB,加上LES子网格模型、动网格、6-DOF求解,需3-5倍余量 |
| 系统盘 | 2× 7.68TB U.2 NVMe SSD(企业级,3 DWPD,RAID 1) | 操作系统与编译环境,高可靠性 |
| 计算缓存 | 4× 15.36TB U.2 NVMe SSD(PCIe 4.0×4,RAID 0或LVM条带化) | 临时存储网格文件、瞬态结果(每时间步输出,TB级),总吞吐>20GB/s |
| 数据存储 | 100TB NVMe-oF全闪存阵列(或本地8×16TB SATA SSD RAID 6) | 归档历史算例,容量型 |
| 加速卡 | 2× NVIDIA RTX 6000 Ada 48GB | 后处理实时渲染(ParaView GPU加速),AI流场重构训练 |
| 网络 | 双万兆以太网(管理)+ 1× 100GbE(数据导出) | 向集群/存储服务器传输TB级结果 |
| 电源 | 2000W钛金认证冗余电源 | 双路EPYC+满配内存功耗>800W,需高余量 |
性能预期:
-
5亿网格非定常DES:单时间步~30-60秒,1000步/天
-
内存带宽实测:~900GB/s(Stream Triad),确保稀疏矩阵求解不受限
方案B:AI+CFD融合开发工作站——异构计算型
定位:开发文中提到的"AI从静态CFD生成动态尾流"应用,支持PINN训练、实时流场渲染。
| 组件 | 配置规格 | 选型逻辑 |
|---|---|---|
| CPU | AMD Ryzen Threadripper PRO 7995WX(96核,5.3GHz) | 单核高频保障GUI响应,多核并行数据预处理 |
| GPU | 4× NVIDIA RTX 4090 24GB(或2× RTX 6000 Ada 48GB) | 四卡NVLink/PCIe桥接,总显存96-192GB,支持大batch PINN训练 |
| 内存 | 768GB DDR5-5600 ECC(12×64GB) | 加载大规模体数据(4D时空张量)进行训练 |
| 存储 | 系统盘:2TB NVMe;数据盘:8× 4TB NVMe RAID 0(软RAID) | 高速读取CFD训练数据集(TB级HDF5文件) |
| 显示 | 2× NVIDIA RTX A5500(或1× RTX 6000 Ada)专业卡 | 双路4K输出,支持3D Vision立体显示流场 |
| 网络 | 10GbE(接入集群获取CFD源数据) | 快速下载大规模算例 |
软件栈优化:
-
安装NVIDIA Modulus框架,利用TensorRT优化推理速度
-
配置ParaView 5.12+ with CUDA加速,实现亿级网格实时旋转/切片
方案C:战术级快速评估工作站——机动-尾流耦合仿真
定位:面向军事科研单位,快速评估特定机动动作(眼镜蛇、桶滚)的瞬态气动力与尾流特征,支持6-DOF实时耦合。
| 组件 | 配置规格 |
|---|---|
| CPU | Intel Xeon W9-3495X(56核,4.8GHz)或 AMD TR PRO 7985WX(64核) |
| 内存 | 512GB DDR5-4800(8×64GB) |
| 存储 | 4× 3.84TB NVMe SSD(RAID 0,用于动网格频繁的checkpoint写入) |
| 专业卡 | 1× NVIDIA RTX A4500 20GB(兼顾计算与显示) |
| 特色配置 | 预装Pointwise/ANSYS Fluent流固耦合模板,支持动网格+6DOF开箱即用 |
四、关键技术优化建议
1. 非定常CFD性能调优
内存优化:
-
使用GAMG(Geometric-Algebraic Multi-Grid)求解器替代PCG,减少内存占用30%
-
启用内存池分配(OpenFOAM的
malloc优化编译选项),避免频繁new/delete
并行策略:
-
采用METIS/Scotch进行网格分解,最小化界面单元数(<5%)
-
对于LES的频谱求解,确保每节点网格量>50万,平衡通信与计算
I/O加速:
-
使用ADIOS2库替代标准IO,支持异步写入(计算与存储重叠)
-
输出格式选择binary而非ASCII,体积减少70%
2. AI融合工作流优化
数据管道:
-
CFD结果→HDF5格式→NVIDIA DALI数据加载器→GPU训练,避免CPU解码瓶颈
-
使用NVIDIA IndeX进行超大体积数据(>100GB)的交互式可视化
混合精度训练:
-
PINN训练使用TF32/FP16,在RTX 4090上可获得相比FP32 2-3倍加速,显存占用减半
3. 可靠性设计
非定常仿真的容错:
-
配置每100时间步自动checkpoint,防止意外断电丢失数天计算成果
-
使用RAID 10存储活跃算例,平衡性能与冗余
热管理:
-
非定常CFD满负荷运行时CPU持续100%负载,需360水冷确保全核频率不降频
-
机房环境温度控制在22±2℃,避免内存高温降速(DDR5温度>80°C时触发保护)
五、总结
从文中即梦Seedance 2.0对CFD云图的"理解"可以看出,非定常流场仿真正在从单纯的数值计算,走向"仿真+AI"的融合范式。对于航空工程与国防科研单位,这意味着:
-
前端需要支持数十亿网格、微秒级时间步的 brute-force LES/DES算力(方案A)
-
后端需要大显存GPU集群支撑AI流场重构与实时可视化(方案B)
-
全流程需要高带宽存储应对TB级瞬态数据的读写压力
当工作站能够单机承载原本需要超算中心的非定常全机仿真,当AI能够在秒级从静态云图推演动态尾流,战斗机机动轨迹上的每一道涡流,都将成为可计算、可预测、可掌控的数字资产。
如需针对特定机型(如F-22)的精细外流场仿真,或特定机动(过失速机动、尾旋)的专项硬件方案,可提供具体雷诺数、马赫数与网格分辨率要求,我们将输出定制化配置清单
【UltraLAB 解决方案事业部】
咨询专线:400-7056-800
微信号:xasun001
上一篇:没有了


